Metaphors We Listen With
It is a difficult matter to define tone quality in words; we must encroach upon the domain of sight, feeling, and even taste.
— Nikolai Rimsky-Korsakov (1913)
A sound’s timbre describes its harshness or softness, its dullness or brightness.
— Jean-Jacques Rousseau (1765)
Timbre is notoriously difficult to define, and even harder to talk about. Yet people do talk about it, especially musicians, composers, producers, instrument makers, and with surprising consistency. Previous studies have converged on a small number of recurring semantic dimensions, which can be interpreted broadly in terms of brightness/sharpness (or luminance), roughness/harshness (or texture), and fullness/richness (or mass). Saitis and Weinzierl (2019) provide a comprehensive review of the field.
These semantic descriptions of timbre embody conceptual representations, allowing listeners to talk about subtle acoustic variations through other, more commonly shared corporeal experiences—metaphors we listen with. The luminance-texture-mass (LTM) model describes how listeners across different languages tend to reach for the same kinds of metaphor.
But how far does this model stretch? And does the way we talk about timbre actually track how we make sounds?
Disembodied Timbres: a study on semantically prompted FM synthesis
Most of what we know about what is called “timbre semantics” comes from studies using acoustic orchestral instruments. Hayes, Saitis, and Fazekas (2022a) asked whether the same conceptual vocabulary applies to sounds with no recognisable physical source: the “disembodied” timbres of digital synthesis.
Synthesiser controls typically map to low-level signal processing parameters rather than perceptual concepts, making intuitive sound design difficult, a problem compounded by the growing complexity of commercial instruments. David Wessel first proposed using a timbre space as a control interface, which worked well for additive synthesis given its linearity. FM synthesis is harder: its parameters interact nonlinearly, so straightforward mappings from perceptual or semantic timbre dimensions to synthesis controls are more difficult to derive, and the relationship between semantic dimensions and underlying perceptual representations remains unclear.
In a novel experimental paradigm, experienced sound designers programmed an FM synthesiser in response to semantic prompts, and provided semantic ratings on the sounds they created. We collected 1,407,604 publicly available posts from a popular synth forum, and looked for adjectives co-occuring with the terms sound, sounding, tone, and timbre. An initial list of 96,277 adjectives were independently pruned by two raters down to a list of 27 unipolar semantic scales, including “bright,” “thick” and “rough” selected as synthesis prompts.
Exploratory factor analysis of the semantic ratings recovered five dimensions. The first two broadly echoed the LTM model: luminance and texture merged into a single “sharpness” factor, while mass appeared as a second independent factor. Three additional dimensions emerged, namely clarity, percussiveness, and rawness, which appear to reflect specific qualities of FM timbres that listeners discriminated.
Semantic prompts left measurable imprints on synthesiser controls. Participants tuning for “brightness” and “roughness” made similar adjustments to the modulator parameters, the FM settings that govern the distribution of spectral energy, consistent with the acoustic correlates observed for these descriptors. “Thickness”, by contrast, was pursued through the amplitude envelopes, shaping the sustain and temporal decay of the sound. Word affect also left its mark: adjectives with stronger emotional valence (positive or negative) tended to produce sounds with more energy in the higher frequencies and greater inharmonicity, echoing earlier findings.

- Spearman’s ρ correlations
- : *p < 0.05; *: *p < 0.01; **: *p < 0.001
- F = factor, A = attack; D = decay; S = sustain; R = release; T = tuning; V = volume; 1 = carrier; 2 & 3 = modulators
Perceptual and semantic scaling. Using FM sounds created in the prompted synthesis study, and the same 27 unipolar semantic scales, Hayes, Saitis, and Fazekas (2021) further collected standard pairwise dissimilarity and semantic ratings.
Multidimensional scaling of the dissimilarity data revealed three-dimensional perceptual spaces, but with a notable finding: musicians and synthesiser-experienced listeners organised the sounds differently from non-experts, suggesting that prior experience shapes the perceptual structure of electronic timbres in ways not typically seen with acoustic instruments.
Semantic ratings, by contrast, were remarkably consistent across expertise groups. Exploratory factor analysis recovered two factors: one showing strong loadings for mass and darkness, and the other with texture. These are congruent with the LTM model, but their order suggests that mass better characterises stimulus variance here, largely in line with the main study reported above. Indeed, the mass factor showed strong correlations with all MDS spaces’ first dimensions, and these correlated strongly with the second principal component of stimuli modulation power spectra.
The overall conclusion is that electronic timbres may draw on perceptual attributes distinct from those governing acoustic instrument sounds, that expertise modulates perception but not semantic description, and that this gap points to attributes in the sounds that the adjective set may not fully capture.
timbre.fun: A gamified interactive system for crowdsourcing a timbre semantic vocabulary
Based on the prompted synthesis task, Hayes, Saitis, and Fazekas (2022b) developed timbre.fun, a gamified web platform where anyone can explore a two-dimensional synthesiser space and tag the sounds they create with semantic prompts mined from synthesis forums. Debuted at the 2021 Edinburgh Science Festival, the platform attracted nearly 800 users from 35 countries, yielding hundreds of tagged sounds. Even with this more casual, diverse sample, the emergent structure of the data aligned meaningfully with prior lab findings: prompts like sharp, bright, and harsh clustered together in synthesis space and in acoustic feature space—PCA and k-means clustering on audio features revealed two distinct spaces, consistent with the LTM luminance-texture grouping.

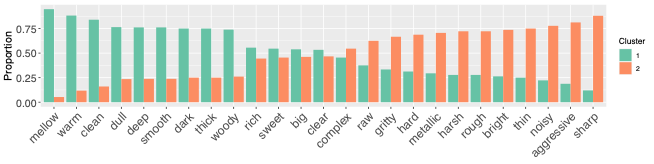
- cluster 1: more energy in low frequencies, and clear peaks in the spectrum
- cluster 2: a flatter spectrum with more high frequency energy
Very interestingly, the emotional arousal connotation of timbral metaphors proved to be a reliable predictor of the acoustic character of the sounds that people created. Using published word affect norms, valence, arousal, and dominance scores were obtained for each prompt. Each affect dimension was treated as a binary classification problem, fitting an SVM (RBF kernel) on either acoustic principal components or synthesiser parameters as input. A binomial test using the no-information rate as the null hypothesis suggested the result for arousal was statistically significant (accuracy: synth parameters 73.1%, acoustic PCs 71%; p < 0.001).
Timbre semantic associations vary both between and within instruments
An empirical study incorporating register and pitch height
Editor’s note: some text has been taken from a summary of the work published elsewhere.
Reymore, Noble, Saitis, Traube, and Walmark (2023) looked at the variations in timbre within an instrument and between different instruments, and the corresponding semantic associations. These variations depend on dynamics, pitch, articulation, duration, vibrato, technique, and other parameters. Register-dependent descriptions of instruments’ timbres characterize instruments based on register, or a part of the instrument’s range, such as the rumbling, thick, and muddy low notes of the piano versus the tinkling, thin, and clear highest notes. This relationship is further complicated by the varying tessituras, or range of playable notes, for different instruments (for example, the flute’s lowest notes overlap with the bassoon’s highest notes, as shown below).
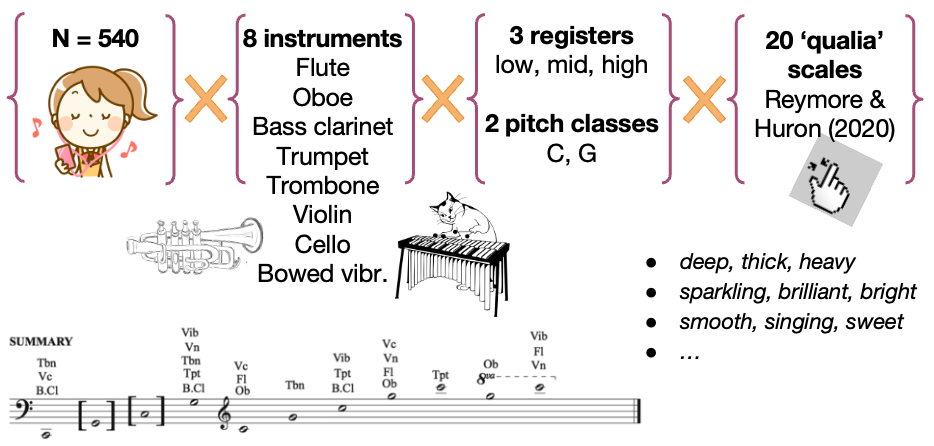 To address these variations, we designed an experiment to examine the effect of register on instrumental timbre semantics, with additional analysis relating specifically to pitch height. Four of the instruments (violin, bass clarinet, trombone, and vibraphone) were selected based on the ACTOR CORE (Composer-Performer Orchestration Research Ensemble). Vibraphone sounds were bowed, rather than struck, to maintain consistency of excitation type. We then added flute, oboe, trumpet, and cello in order to balance the range of the stimuli and to maximize the variability of orchestral timbres tested. We note that the vibraphone was included precisely because it is an outlier—the only percussion instrument, idiophone, non-default technique, and non-standard orchestral member, offering useful variability for studying how instrument type interacts with register-semantic relationships. We used 20 semantic scales (sets of descriptive adjectives) derived from Reymore & Huron (2020):
To address these variations, we designed an experiment to examine the effect of register on instrumental timbre semantics, with additional analysis relating specifically to pitch height. Four of the instruments (violin, bass clarinet, trombone, and vibraphone) were selected based on the ACTOR CORE (Composer-Performer Orchestration Research Ensemble). Vibraphone sounds were bowed, rather than struck, to maintain consistency of excitation type. We then added flute, oboe, trumpet, and cello in order to balance the range of the stimuli and to maximize the variability of orchestral timbres tested. We note that the vibraphone was included precisely because it is an outlier—the only percussion instrument, idiophone, non-default technique, and non-standard orchestral member, offering useful variability for studying how instrument type interacts with register-semantic relationships. We used 20 semantic scales (sets of descriptive adjectives) derived from Reymore & Huron (2020):
| deep, thick, heavy | brassy, metallic | woody | pure, clear, clean | hollow |
| smooth, singing, sweet | raspy, grainy, gravelly | muted, veiled | resonant, vibrant | watery, fluid |
| project, commanding, powerful | ringing, long decay | sustained, even | percussive (sharp beginning) | focused, compact |
| nasal, buzzy, pinched | sparkling, brilliant, bright | open | shrill, harsh, noisy | airy, breathy |
Register and instrument influence most scales. For certain sets of terms, the results showed similar patterns across registers for all the instruments, for instance, deep/thick/heavy was consistently rated highest in the low register, whereas sparkling/brilliant/bright received the highest ratings in the high register. For other terms, relationships between register and semantic associations depended on the instrument, for example, the trombone was rated most smooth/singing/sweet in its higher register, whereas the trumpet received increased ratings for smooth/singing/sweet in its middle register. There was little variance among registers for the descriptors brassy/metallic and sustained/even across all the instruments. Unlike the other instruments, the vibraphone displayed very little semantic variation across registers.
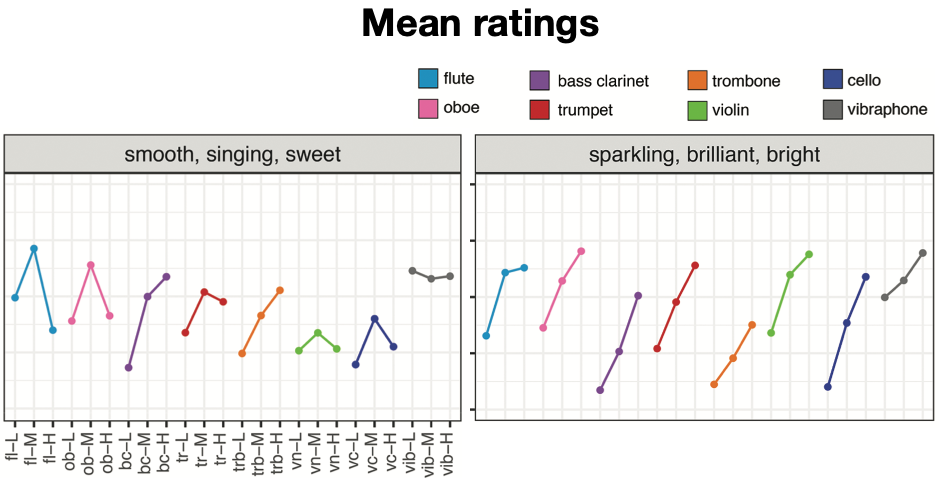
Linear mixed effects models confirmed that register and instrument played significant roles for most models, though not for brassy/metallic. Some variables only indicated statistically significant main effects for one of those (register was significant for open, but not instrument, and register was not significant for focused/compact, nasal/buzzy/pinched, and sustained/even, but instrument was).
Pitch height explains more variance than register. Data were analysed in several ways, including exploratory hierarchical clustering, to show relationships among stimuli within the 20 semantic categories. These clusters were not easily explained by instrument, instrument family, or Hornbostel-Sachs categories for organology (apart from the vibraphone, which stands alone in that its low, medium, and high notes are clustered together). Rather, they are better interpreted using pitch height, with a high cluster (G5–C7), a medium-high cluster (C5–G5), a medium-low cluster (G3–G4), and a low cluster (C2).
Thus, we focused in our post hoc analysis on critically comparing pitch height and register. Two models were considered for each semantic scale, one using only pitch height as a fixed effect and one using only register as a fixed effect. We found that the former produced significantly better goodness-of-fit than the latter, i.e., explaining more variance in semantic ratings. Both types of models included the random effects structures determined through the initial analysis; however, the pitch height models included pitch height as a random slope, whereas the register models included register as a random slope. As with register, pitch height was modeled as a categorical variable.
Summary. These findings confirmed some differences in semantic category ratings within instrument ranges and between different instruments. Register only accounted for 5% or more of the variance for only 8 of the 20 categories, a relatively small impact. Interestingly, bass clarinet and trombone showed increased average ratings for smooth/singing/sweet in their higher register, whereas flute, oboe, trumpet, violin, and cello displayed highest average ratings for smooth/singing/sweet in their middle register. Seeing as brassy/metallic ratings had little variation across the stimuli, it is possible that since the majority of participants were nonmusicians, their variable knowledge of the terms brassy/metallic may have influenced those ratings. This opens up an avenue for future research on how musicians and nonmusicians potentially apply semantic terms to timbre differently, and how music training impacts timbre description. Future research could also expand this study to other instruments as well as variations in dynamics, articulations, or playing/extended techniques, and thus a broader range of musical timbres.
Related publications
Hayes, B., Saitis, C., & Fazekas, G. (2022a). Disembodied timbres: A study on semantically prompted FM synthesis. Journal of the Audio Engineering Society, (5), 373-391.
Hayes, B., Saitis, C., & Fazekas, G. (2021). Perceptual and semantic scaling of FM synthesis timbres: Common dimensions and the role of expertise. Proceedings of the 16th International Conference on Music Perception and Cognition, 1–2.
Hayes, B., Saitis, C., & Fazekas, G. (2022b). timbre. fun: A gamified interactive system for crowdsourcing a timbre semantic vocabulary. Proceedings of the 24 International Congress on Acoustics (ICA), 1–10.
Reymore, L., Noble, J., Saitis, C., Traube, C., & Wallmark, Z. (2023). Timbre semantic associations vary both between and within instruments: An empirical study incorporating register and pitch height. Music Perception, 40(3), 253-274.