NIME 2026 WORKSHOP
Tuesday 23 June 2026, 09:00-13:00
LUL Here East Campus in London’s Olympic Park
Register here! --> New Deadline 15 June AoE
From Tacit to Tokenised: Critical Perspectives on AI Text-to-Audio Interfaces
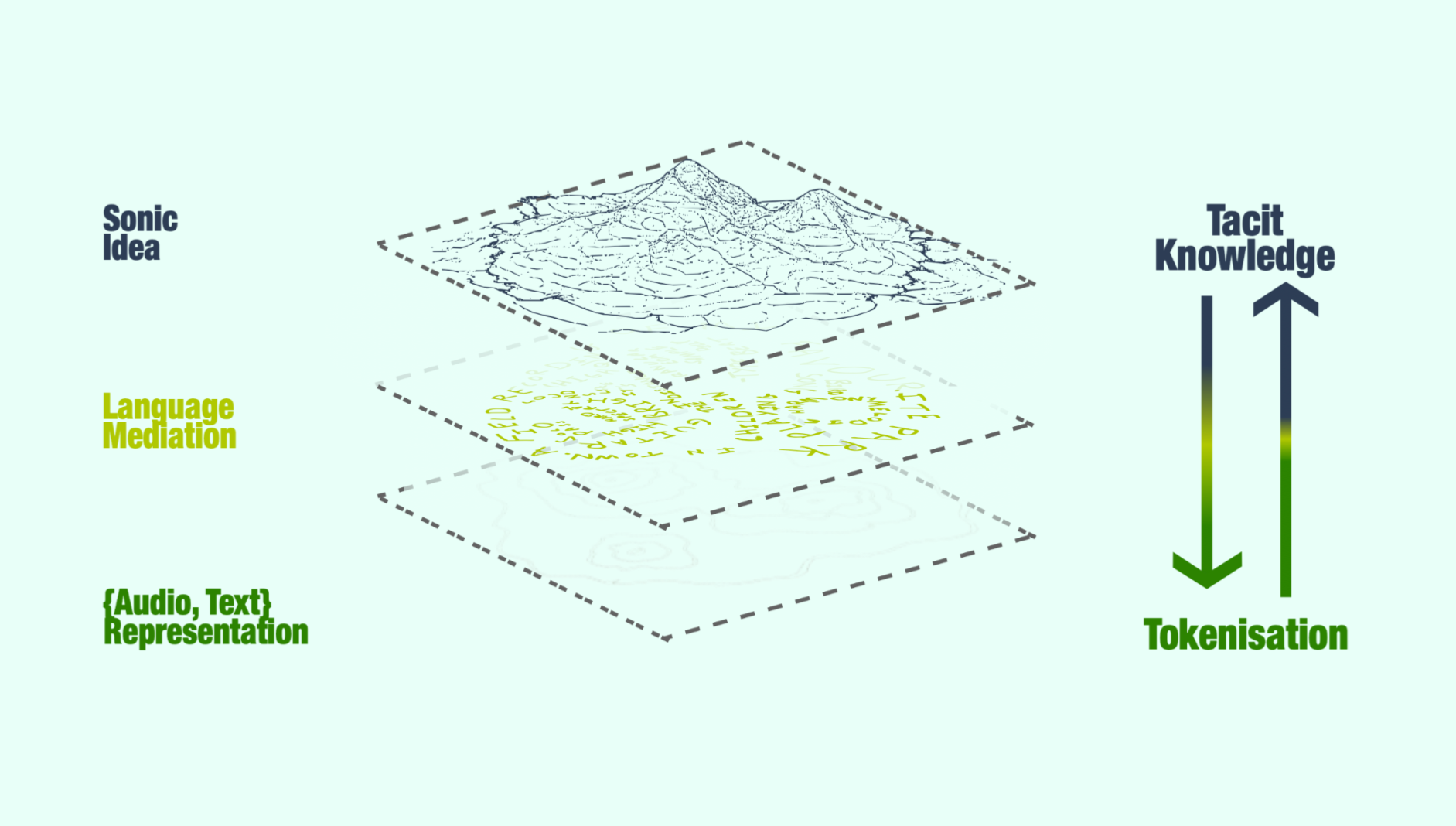
This half-day workshop will explore, through hands-on activities and collective discussion, how generative AI text-to-sound systems attempt to fix relations between words and sound, and how these mappings intersect with the diverse sonic cultures, languages, pedagogies, and histories that shape musical practice. In doing so, participants and organisers will reflect on how we talk about music, how we negotiate audio representations, and the values we can construct in AI systems, considering the global implications and hegemonies being introduced by multi-national AI giants in shaping the way we conceptualise sound.
Specifically, participants will engage with two alternative semantic mediation strategies for generative sound: natural language and embodied gesture. Contrasting text-to-sound and gesture-to-sound generation is particularly meaningful for NIME, where gesture has long been central to questions of embodiment and mapping. We foreground first- and second-person methodologies, inviting researchers to examine musical interaction design and AI practices from within, positioning their own experiences and creative processes as sites of critical inquiry.
In terms of natural language, participants will interact with a lightweight text-conditioned generative audio system, using any text descriptions (prompts) that feel natural to them, processed by pre-trained text embeddings. We have also designed a version where semantic audio descriptors such as ‘brightness’ or ‘warmth’ can be used to manipulate latent representations of a generative audio model. In terms of embodied gesture, participants will use any movements they choose, detected by their laptop camera and processed by pre-trained pose estimators connected to a lightweight gesture-to-audio generative system.
You can read the full workshop description here.
Call for Participation
We invite musicians, researchers, artists, designers, educators, and creative practitioners from NIME and off-NIME communities, who are interested in representations of sound and how AI systems learn and interpret text-based descriptions of audio.
Interested attendees should submit a brief expression of interest (150–200 words), outlining their background and motivation for attending.
We particularly encourage applications from people who represent diverse musical and cultural contexts.
As part of the workshop, the organisers will conduct an ethnographic study of participants’ experiences and reflections, including observational notes, contributions to a shared ideation canvas, photographs of the workshop process, and recordings of short performances with generated audio. Participation in data collection will be voluntary and subject to informed consent.
Important Dates
- Expression of interest / Registration: 15 June 2026 AoE
- Notification of acceptance: 17 June 2026 AoE
- Remote technical preparation (see Schedule): 19 & 22 June 2026
- Workshop: 23 June 2026, 09:00–13:00
- Conference: 24–26 June 2026
Workshop Schedule
Code of Conduct
One of the primary goals of this workshop is to foster an inclusive space for collaboration, creativity, and innovation. All skill levels and backgrounds are welcome.
We ask that all participants familiarize themselves with the NIME Conference Code of Conduct and follow this conduct in all communications, in-person and online.
Please reach out immediately to one of the workshop organizers in-person or online/via email if you experience something that doesn’t feel right.
Organisers
Hello! We are a team of timbrologists, musicians, designers, and researchers working at the intersection of Music, AI, HCI, and NIME. We bring together perspectives from timbre research, human–computer interaction, instrument design, creative machine learning and AI, performance and artistic practice, and critical and cultural approaches to music and technology.
Charalampos Saitis (he/him) is an Assistant Professor of Digital Music Processing at the Centre for Digital Music at Queen Mary University of London. His work combines methods from psychoacoustics, music informatics, and human–computer interaction to inform the design of new musical interfaces and AI-driven creative tools, with a particular focus on how timbre is conceptualised in the design and use of new music technologies and instruments. He has published widely on timbre perception and semantics and has been actively involved in the NIME and ISMIR communities.
Fabio Morreale (he/him) is a scholar and musician working in the intersection of NIME, AI, Ethics, and Philosophy of Technology. He has an MS in Computer Science, a PhD in HCI, and now works as a Staff Research Scientist at Sony AI. Prior to that, he was a Senior Lecturer in Algorithmic Composition at the University of Auckland in New Zealand. He also worked as a postdoc at Queen Mary University of London in the Augmented Instruments Lab. He has been publishing at NIME since 2014 and is an active member of the community.
Landon Morrison (he/him) is an Assistant Professor of Music Theory at the Eastman School of Music at University of Rochester, New York. He has previously worked as a post-doctoral researcher at Imperial College London and as a college fellow and lecturer at Harvard University. His research, which has been published in leading academic journals, draws on methods from music and media studies to examine technocultural mediation in contemporary sonic practices.
Ashley Noel-Hirst (he/him) is an artist and fourth-year PhD student at the Centre for Digital Music at Queen Mary University of London. He has an MMus in Sonic Arts from Goldsmiths University of London and has created interactive and generative music for several festivals, including SXSW (US) and Being Human (UK). In his research, Ashley draws on AI, HCI and ethnomusicology to investigate the impact of timbre representations in AI systems on sample-based music-making.
Rebecca Fiebrink (she/her) is Professor of Creative Computing at the Creative Computing Institute at University of the Arts London. She has been conducting research on integrating machine learning and AI in human creative practices, including the design of new musical instruments, for over twenty years. She is the creator of numerous tools for creative and embodied machine learning, including Wekinator, which have tens of thousands of users. She has organised popular workshops at past NIME conferences as well as at ISMIR, CHI, IUI, NeurIPS, and others.
Joseph Meyer (they/their) is a second-year PhD student and Associate Lecturer at UAL’s Creative Computing Institute, researching interactive neural audio synthesis and movement-to-sound mapping. Their work emphasizes techniques to lower barriers to entry for artists to access and use generative ML systems. Recently, they have been developing methods to make generative models more controllable and interactive, and to increase the novelty of generated output.
Courtney N. Reed (she/her) is an Assistant Professor of Digital Technologies and Creative Futures at Loughborough University London. Her work focuses on vocalist-voice relationships and how singers conceptualise their bodies and voice in the design and use of digital musical instruments. She is an expert in subjective methodologies and experiential querying and has previously led workshops on sensory experiences at NIME, TEI, and CHI. She is especially fascinated by ambiguity and metaphors in working with and communicating abstract, embodied sensory experiences.
